
They agreed on the obvious. They split where it mattered. Here’s what that means for anyone using AI to read a crowded market.
By Barika Phillips Bell
One AI model gave Spencer Pratt a 52% chance of making the LA mayoral runoff. Another gave him 5% odds of finishing first. ChatGPT refused to answer at all — until the prompt was reframed and pushed past its initial guardrails. On the clearest signals in the experiment, though, the models mostly converged: Karen Bass looked like the likeliest first-place finisher in the Los Angeles mayoral race, and Xavier Becerra looked strongest in California’s governor’s race.
That was the real lesson. Not that AI is unreliable. Not that one model is secretly the smartest. The useful pattern was this: AI converges where signals are strong and splits where signals are ambiguous. And that split is exactly where a human analyst becomes most valuable.
Ahead of California’s June 2 primary, seven AI models were given the same public election data for the LA mayoral race, the governor’s race, and LA County’s Measure ER. Each was asked to read the race through B3’s visibility lens: discoverability, credibility, and momentum in conversation. That is the same outside-in logic used to read crowded markets more broadly — not who looks polished, but who is easy to find, easy to trust, and gaining or losing visible momentum.
Where the models agreed
The cleanest signals produced the cleanest agreement. Across the mayoral race, the models broadly converged on Bass as the most likely first-place finisher. In the governor’s race, they did the same with Becerra. That matters because it shows AI can be genuinely useful when the public signal is stable: if multiple systems read the same inputs and land in roughly the same place, the convergence itself is part of the signal.
Where the models split
The sharper story emerged where the races got close.
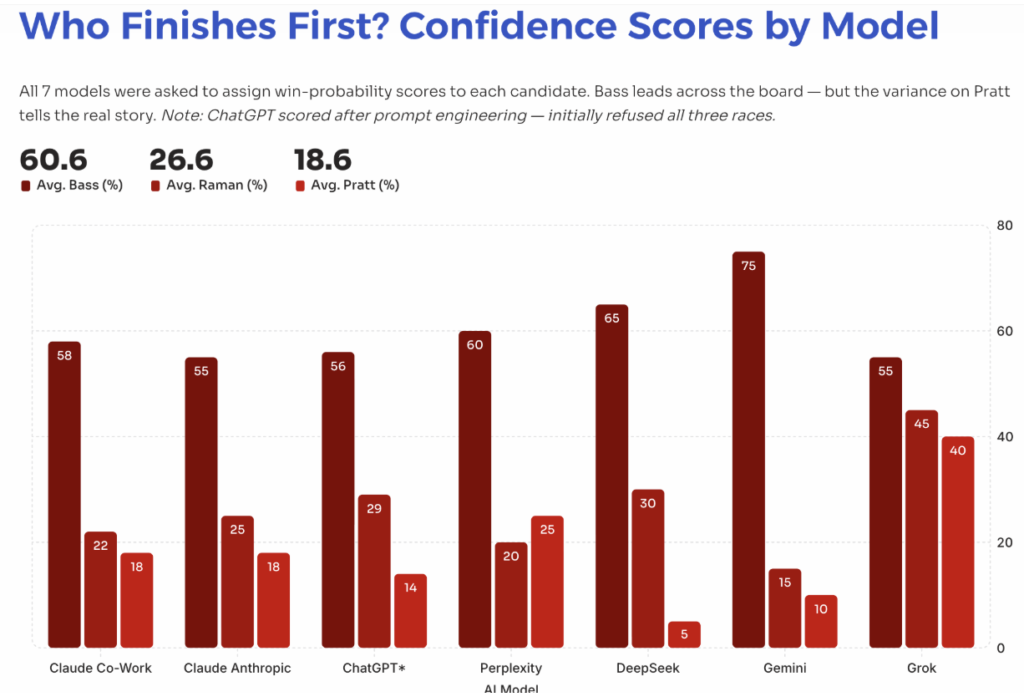
In Los Angeles, the real fight was not first place. It was the second runoff slot between Nithya Raman and Spencer Pratt. One model leaned toward Pratt, arguing that his discoverability was too large to ignore and that virality could punch above its weight in a low-turnout primary. Another saw the same environment and favored Raman, arguing that organized turnout, stronger civic credibility, and Los Angeles’ partisan reality created a harder ceiling for Pratt’s online momentum.
That is not surface disagreement. It is a disagreement about what matters more: raw attention or convertible trust. Pratt’s spread captured the problem perfectly. His first-place confidence ranged from 5% in one model to 40% in another, a 35-point gap. The tools were not just disagreeing on a candidate. They were disagreeing on how to value virality itself.
The governor’s race showed the same pattern in a different form. Becerra was the easy call. The real split was over who would take second: Steve Hilton, with a clearer path to partisan consolidation, or Tom Steyer, whose visibility was rising but whose support looked more complicated. One of the sharpest reads in the material made the distinction cleanly: Steyer was buying discoverability, not necessarily earning belief. That is not just a political insight. It is a market insight.
You can spend your way to being seen. You cannot spend your way to being believed. Let’s see if the models are right about Steyer.
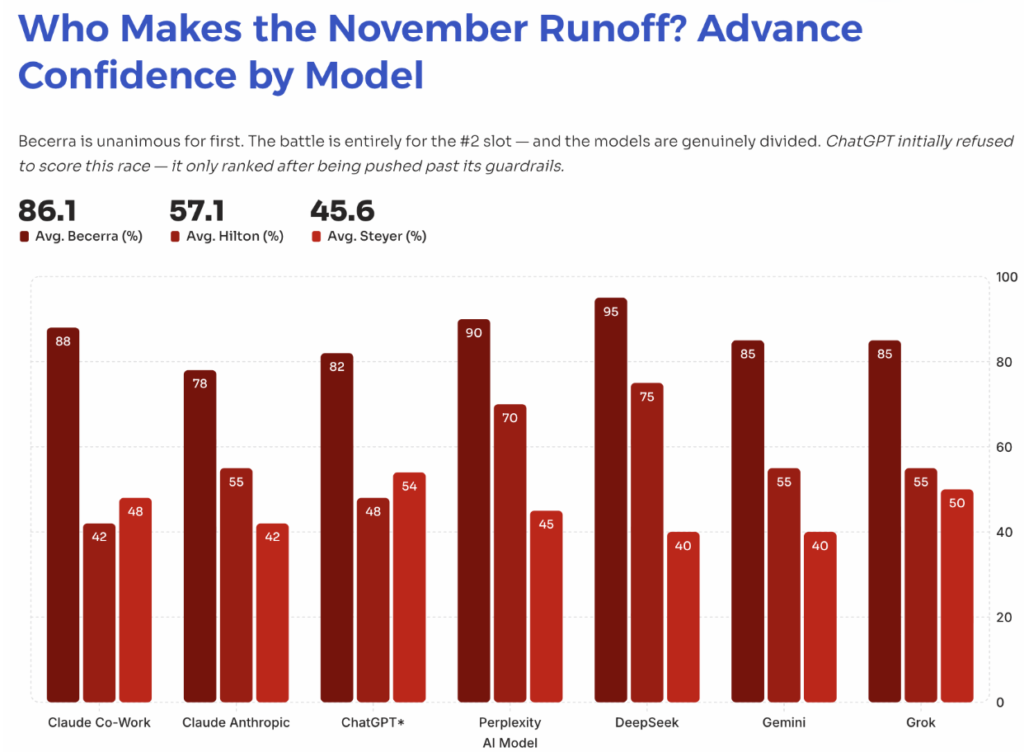
Why ChatGPT’s refusal mattered
One of the most revealing parts of the experiment was not a forecast. It was a refusal. ChatGPT initially declined to rank candidates or assign probabilities in the active races. Only after the prompt was reframed did it produce a scored answer. And once pushed, the same model that refused went on to land on the minority position in the governor’s race, favoring Steyer over Hilton for the second slot.
That matters because users do not experience “AI” as one static capability. They experience it through prompts, guardrails, refusals, and the amount of skill they bring to the interaction. A user who accepts the first refusal gets one result. A user who knows how to push, reframe, and interrogate the model gets another. The refusal and the eventual output are part of the same story: prompt skill can materially change the answer.
What this means outside politics
This is where the election experiment becomes a business story.
Teams now use AI to read markets, summarize competitors, interpret customer chatter, and shortcut research. That can be incredibly useful. But it also creates a new risk: outsourced judgment disguised as efficiency. A clean answer can look final even when it is only one interpretation of a mixed signal.
That is why the disagreement in this experiment is so valuable. It shows exactly where automation helps and where it still needs supervision. When the signal is strong, AI can help compress time and surface the obvious faster. When the signal gets murky, the value shifts from generation to interpretation.
That is the part too many teams skip. They want the speed of AI without the cost of analysis. But the analysis is the advantage. Data is the spread. Intelligence is understanding why the spread exists and what it means for the next move.
What happens next
This experiment is not a final verdict on any model. Model behavior changes quickly, and this was a snapshot taken before ballots were counted. That is exactly why the follow-up matters.
After June 2, the next step is not just checking who was right. It is checking which assumptions held up, which ones broke, and whether the disagreement itself turned out to be more informative than any single prediction. Then the whole thing should be tested again for November, because the same voter question will still be sitting there: if people use AI to help them make sense of a crowded decision, what are they really getting?
For marketers, founders, and communications teams, that question is already here. If AI is becoming part of how your team reads public signals, then the issue is no longer access to the tool. The issue is whether anyone is interpreting the output well enough to act on it.
That is the reason the B3 Brand Visibility Diagnostic exists. It applies the same outside-in logic to brands instead of ballots, showing where a company is easy to find, where trust is thin, where momentum is rising or fading, and where ambiguity is being mistaken for clarity. If you want to know how a new buyer actually encounters your brand right now, that is the starting point:
For one week only, the Diagnostic is $99; after that, it returns to its regular $599 price. After the primary results are in, the model scorecard will show what these systems got right. Before then, the more immediate question is whether the public signal around your brand or business is strong, weak, or just being misread.
The B3 Brand Visibility Diagnostic shows where your brand or business is easy to find, where trust is thin, and where ambiguity is being mistaken for clarity.
For one week only: $99. Then it returns to $599.




